|
Jing Tan (谈婧) I'm a third-year Ph.D. Candidate in MMLab at The Chinese University of Hong Kong, supervised by Prof. Dahua Lin. I work on scene-level visual creation and manipulation using structured representations and multimodal generative models.
|

|
Research (Google Scholar)In my research, I consistently leverage the inherent structure of visual data. In video understanding, I exploit the natural temporal and semantic structure of videos to enable efficient perception. In visual scene generation, I study how structured scene representations support reliable and controllable creation and manipulation of visual content. |

|
Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes Jing Tan, Zhaoyang Zhang, Yantao Shen, Jiarui Cai, Shuo Yang, Jiajun Wu, Wei Xia, Zhuowen Tu, Stefano Soatto CVPR, 2026 (Highlight) project page / code / arXiv We show, in the context of geometric object transformations in scene images, that RL is more suitable than SFT to solve visual editing problems with verifiable rewards, in terms of data efficiency and editing accuracy. |
|
Imagine360: Immersive 360 Video Generation from Perspective Anchor Jing Tan*, Shuai Yang*, Tong Wu, Jingwen He, Yuwei Guo, Ziwei Liu, Dahua Lin NeurIPS, 2025 (* equal contribution) project page / code / video / arXiv Imagine360 lifts standard perspective video into 360-degree video with rich and structured motion, unlocking dynamic scene experience from full 360 degrees. |
|
LayerPano3D: Layered 3D Panorama for Hyper-Immersive Scene Generation Shuai Yang*, Jing Tan*, Mengchen Zhang, Tong Wu, Yixuan Li, Gordon Wetzstein, Ziwei Liu, Dahua Lin SIGGRAPH (Conference Track), 2025 (* equal contribution) project page / code / video / arXiv LayerPano3D generates full-view, explorable panoramic 3D scene from a single text prompt. |
|
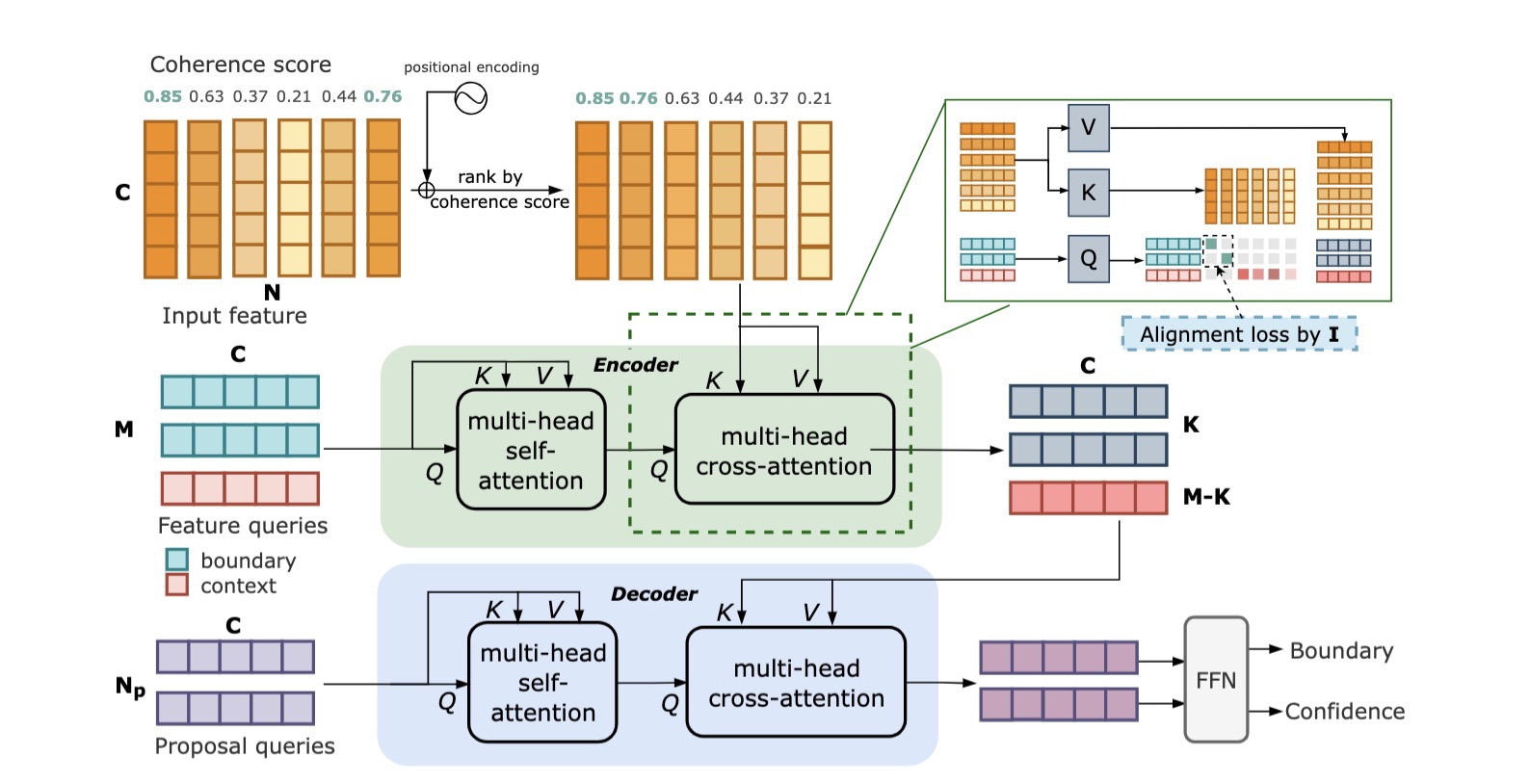
Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection Jing Tan, Yuhong Wang, Gangshan Wu, Limin Wang T-PAMI, 2023 arXiv / code / blog We present Temporal Perceiver (TP), a general architecture based on Transformer decoders as a unified solution to detect arbitrary generic boundaries, including shot-level, event-level and scene-level temporal boundaries. |
|
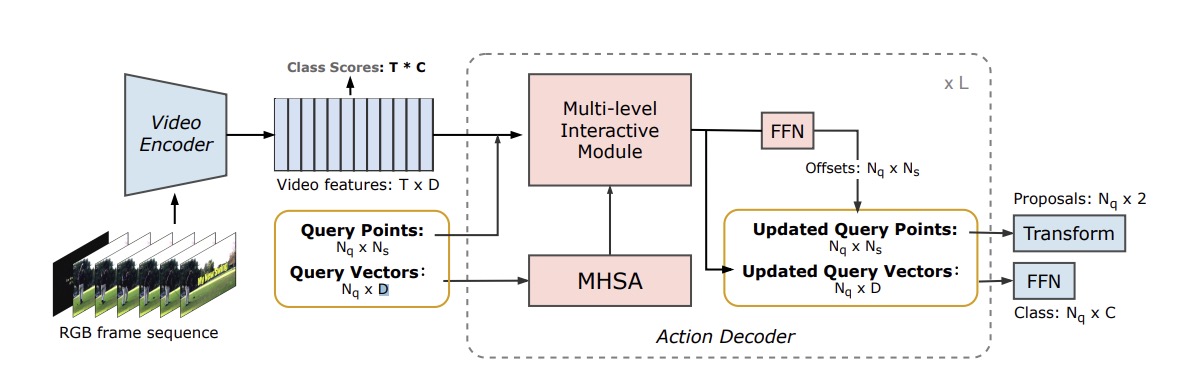
PointTAD: Multi-Label Temporal Action Detection with Learnable Query Points Jing Tan, Xiaotong Zhao, Xintian Shi, Bin Kang, Limin Wang NeurIPS, 2022 arXiv / code / blog PointTAD effectively tackles multi-label TAD by introducing a set of learnable query points to represent the action keyframes. |
|
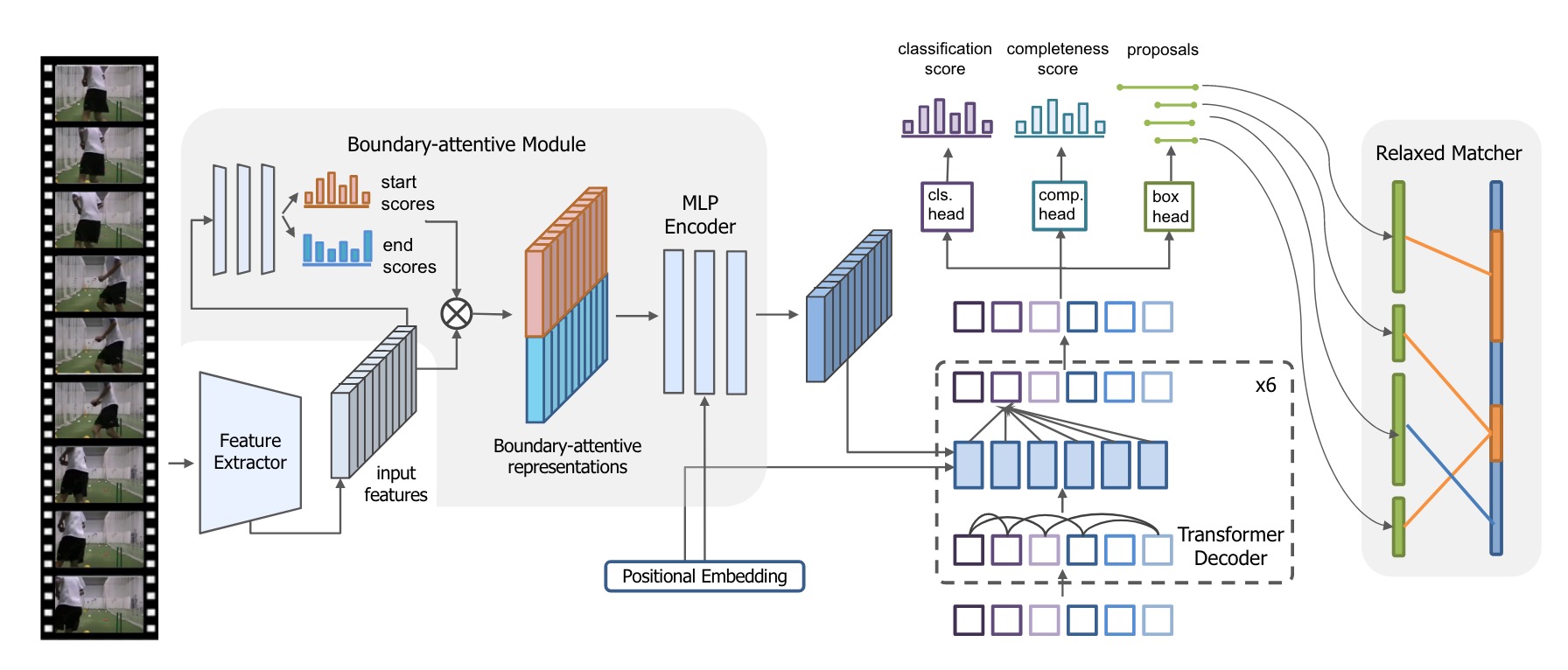
Relaxed Transformer Decoders for Direct Action Proposal Generation Jing Tan*, Jiaqi Tang*, Limin Wang, Gangshan Wu ICCV, 2021 (* equal contribution) pdf / code / blog The first transformer-based framework for temporal action proposal generation. |
Here are some collaborative works on 3D object generation and video generation related topics.

|
SS4D: Native 4D Generative Model via Structured Spacetime Latents Zhibin Li*, Mengchen Zhang*, Tong Wu, Jing Tan, Jiaqi Wang, Dahua Lin SIGGRAPH Asia (TOG), 2025 project page / arXiv / code SS4D is a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. |
|
GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography Mengchen Zhang, Tong Wu, Jing Tan, Ziwei Liu, Gordon Wetzstein, Dahua Lin ICCV, 2025 project page / arXiv / code GenDoP is an auto-regressive model that generate artistic and expressive camera trajectories from text prompts and geometric cues. |

|
IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations Zhibin Li, Tong Wu, Jing Tan, Mengchen Zhang, Jiaqi Wang, Dahua Lin ICLR, 2025 project page / arXiv / code / data IDArb is a Diffusion-based intrinsic decomposition framework for an arbitrary number of image inputs under varying illuminations. |
|
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, Dahua Lin NeurIPS D&B Track, 2024 project page / arXiv / code Camera-controllable human image animation dataset and framework. |
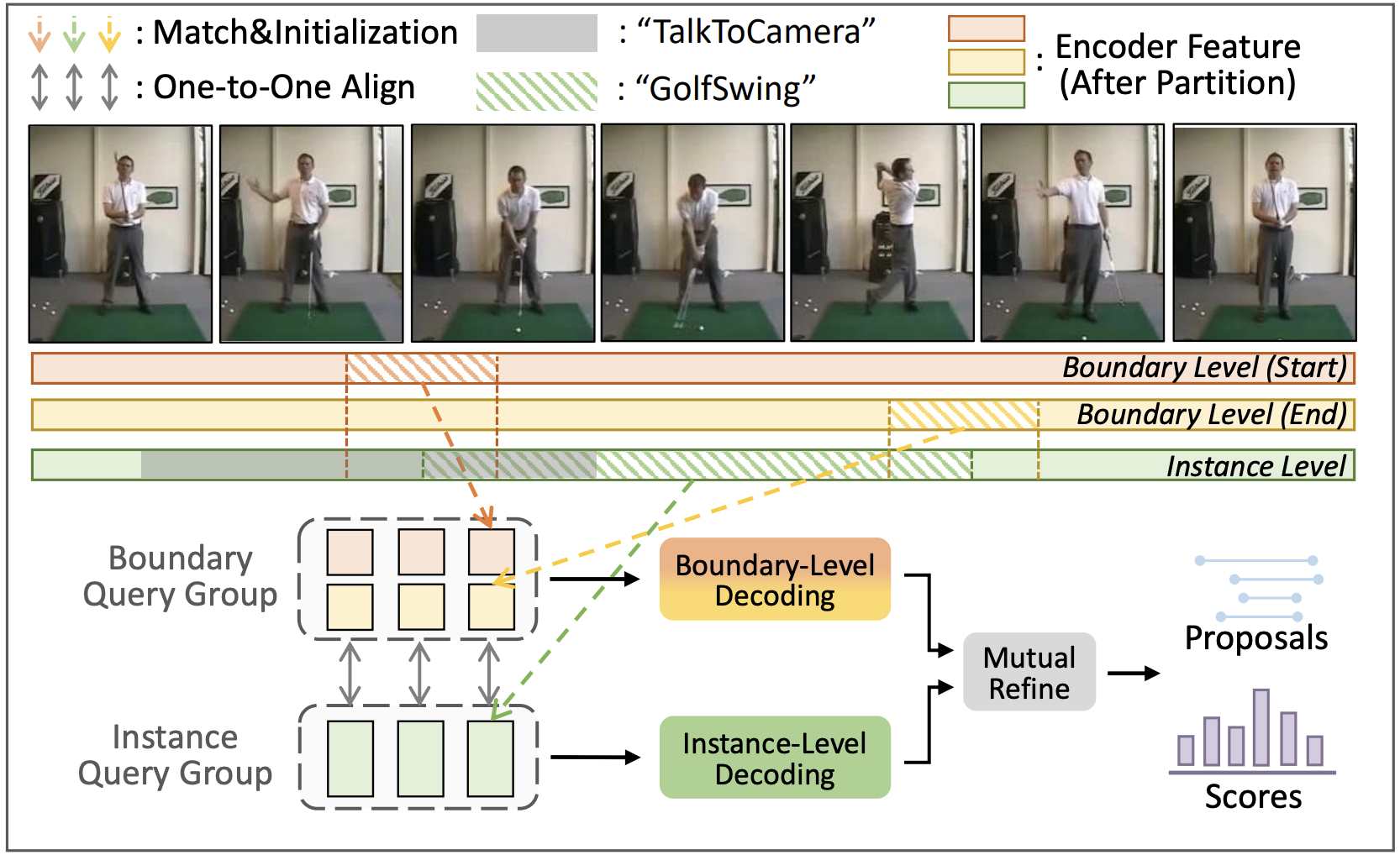
|
Dual DETRs for Multi-Label Temporal Action Detection Yuhan Zhu, Guozhen Zhang, Jing Tan, Gangshan Wu, Limin Wang CVPR, 2024 arXiv / code A new Dual-level query-based TAD framework to precisely detect actions from both instance-level and boundary-level. |
Experience |
|
|
AWS Agentic AI Applied Scientist Intern June 2025 – Nov. 2025 Bellevue, WA, US |
|
|
Tencent, PCG Research Intern Dec. 2021 – Mar. 2023 Beijing, China |
|
Selected Honors & Awards
|
Academic Services |
|
Thanks Jon Barron for sharing the source code of this website template. |